



Um pouco de história
Em 2015, o Airbnb teve um problema: eles estavam crescendo e possuiam uma quantidade enorme de dados que aumentava gradualmente. Para alcançar a visão de se tornar uma organização totalmente orientada a dados, eles tiveram que aumentar sua força de trabalho de engenheiros de dados, cientistas de dados e analistas — todos os quais tiveram que automatizar processos regularmente escrevendo jobs programados. Diante desse cenário e da necessidade de efetuar um agendamento de dados de forma robusta, Maxime Beauchemin criou e abriu o código do Airflow com a ideia de que isso permitiria o time do Airbnb criar, iterar e monitorar rapidamente seus pipelines de dados em lote.
Desde o primeiro commit do Maxime naquela época, o Airflow já percorreu um longo caminho. O projeto ingressou na incubadora da Fundação Apache Oficial em abril de 2016, onde viveu e cresceu até se formar como um projeto de nível superior em 8 de janeiro de 2019. Quase dois anos depois, em dezembro de 2020, o Airflow tinha mais de 1.400 colaboradores, 11.230 commits e 19.800 estrelas no Github. Em 17 de dezembro de 2020, o Airflow 2.0 foi lançado, trazendo grandes atualizações e novos recursos poderosos. O Airflow é usado por milhares de equipes de engenharia de dados em todo o mundo e continua a ser adotado conforme a comunidade se fortalece.
Uma breve introdução
O Apache Airflow é uma plataforma para criação, programação e monitoramento de fluxos de trabalho de maneira programática. É totalmente open source e é especialmente útil para arquitetar e orquestrar pipelines de dados complexos. O Airflow foi originalmente criado para resolver os problemas que vêm com tarefas cron de longa execução e scripts pesados, mas desde então cresceu e se tornou uma das plataformas de pipeline de dados de código aberto mais poderosas que existem.
O Airflow tem alguns benefícios importantes, a saber:
-
Dinâmico: Tudo o que você pode fazer no Python, você pode fazer no Airflow.
-
Extensível: O Airflow tem plugins prontamente disponíveis para interagir com a maioria dos sistemas externos comuns. Você também pode criar seus próprios plugins conforme necessário.
-
Escalonável: As equipes usam o Airflow para executar milhares de tarefas diferentes por dia.
Com o Airflow, os fluxos de trabalho são arquitetados e expressos como DAGs ou Directed Acyclic Graphs, logo cada nó da DAG representa uma tarefa específica. O Airflow foi projetado com a convicção de que todos os pipelines de dados são melhor expressos como código e, como tal, é uma plataforma de código onde você pode iterar rapidamente em fluxos de trabalho. Essa filosofia de design com base no código fornece um alto grau de extensibilidade e escalabilidade.
Casos de Uso
O Airflow pode ser usado para criar virtualmente qualquer pipeline de dados em batch, e há uma vasta quantidade de casos de uso documentados na comunidade. Além disso, graças a sua extensibilidade, o Airflow é particularmente poderoso para orquestrar trabalhos com dependências complexas em vários sistemas externos.
Por exemplo, o diagrama abaixo mostra um caso de uso complexo que pode ser realizado com o Airflow. Ao escrever pipelines em código e usar os vários plugins disponíveis do Airflow, você pode se integrar a qualquer número de sistemas diferentes e dependentes com apenas uma plataforma para orquestração e monitoramento.
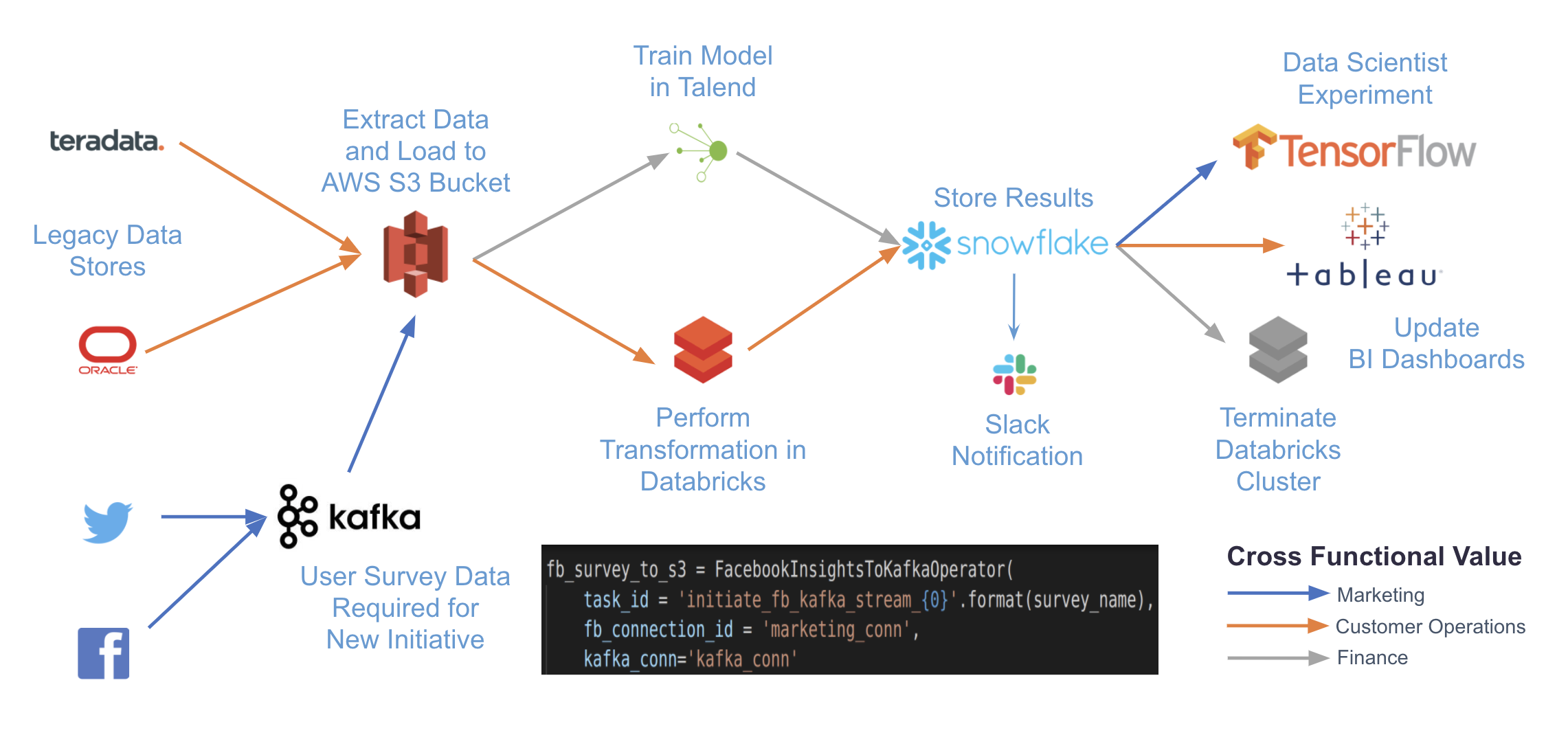
Se você estiver interessado em exemplos mais específicos, aqui estão algumas exemplos de aplicações com o Airflow:
-
Agregação de atualizações diárias de uma equipe de vendas para enviar um relatório diário aos executivos da empresa.
-
Organização e execução de jobs de aprendizado de máquina em clusters externos do Spark.
-
Carreguamento de dados analíticos de um site/aplicativo em um data warehouse de hora em hora.
Principais componentes
Aqui descreveremos os principais componentes do Airflow.
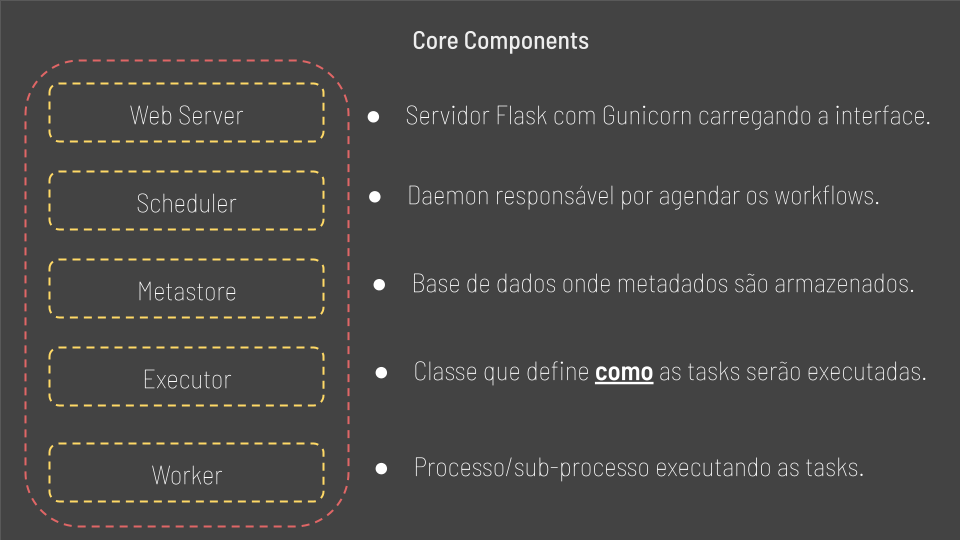
-
Web Server: Responsável por disponbilizar a interface ao usuário.
-
Scheduler: Responsável pelo agendamento dos fluxos de trabalho ou workflows
- Metastore: um banco de dados onde serão armazenados todos os metadados relacionados ao próprio Airflow, mas também relacionados aos nossos dados, pipelines, taks e assim por diante. Normalmente usamos postgres por ser o banco de dados recomendado, mas é possível usar MySQL.
-
Executor: Define como as tarefas serão executadas, seja com kubernetes, Celery ou até mesmo localmente.
- Worker: O processo/sub-processo onde as Tasks são executadas.
Aqui um ponto de atenção.
Existe uma diferença entre o Executor e o Worker. O Executor define como as tarefas devem ser executadas, enquanto o Worker é na verdade o processo que executa as tarefas.
Como funciona o Airflow
Sabemos até agora o que é o Airflow e em que caso utiliza-lo, mas ainda precisamos entender como o Airflow consegue agendar as Tasks nos nossos pipelines de dados.
Existe uma grande chance de na primeira vez que execurtamos o Airflow fazermos isso localmente, e a esse cenário de executar o Airflow em uma única maquina damos o nome de arquitetura de nó unico ou Single Node Architeture
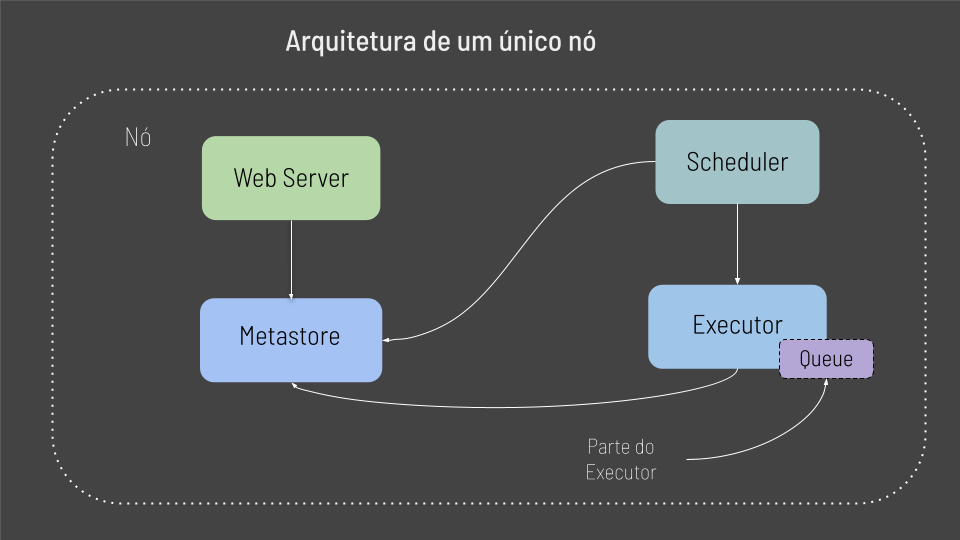
O Web Server requisita dados do Metastore, então o Scheduler pode conversar com o Metastore e com o Executor, para as tarefas designadas serem executadas. Logo o Executor atualiza o status das Tasks no Metastore. Assim todos esses componentes se conversam através do metastore.
Finalmente temos um componente Queue dentro do Executor, e através dele podemos definir a ordem em que as Tasks serão executadas. Tenha em mente que no caso da arquitetura de nó único o Queue faz parte do Executor.
Essa arquitetura funciona bem no caso de experimentos com o Airflow ou caso seja necessário rodar um número reduzido de Tasks.
Porém quando temos várias tasks, como isso funciona? É exatamente por isso que temos a arquitetura multi nós ou Multi Node Architeture.
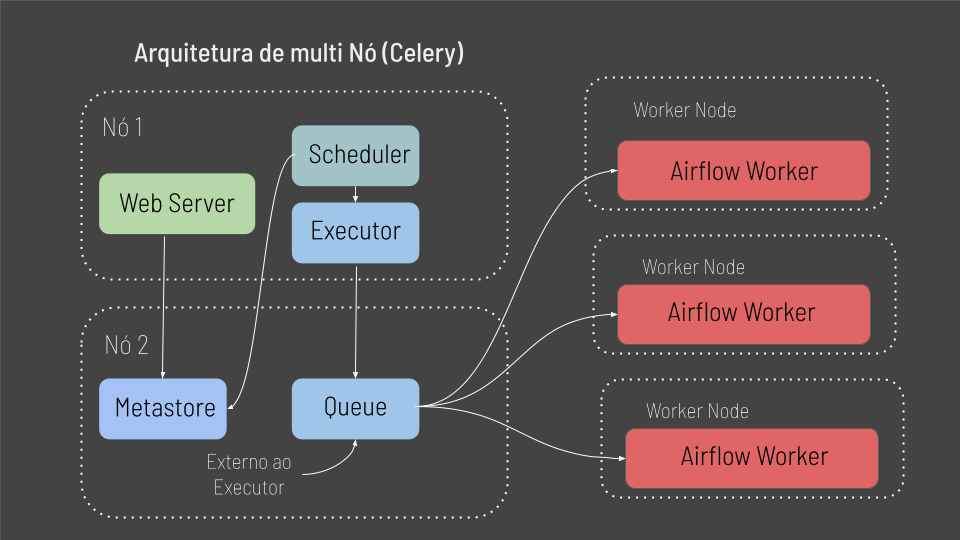
A arquitetura multi nós é disposta em dois nós principais: Nó 1, que é composto pelo Web Server, Scheduler e Executor e o Nó 2 que roda o Metastore e o módulo Queue. E aqui um ponto de atenção.
Observe que diferente da arquitetura de nó unico, o modulo Queue agora é externo ao Executor, então esse modulo pode ser desempenhado por uma ferramente externa como RabbitMQ ou Redis.
No entanto, a principal diferença da aquitetura multi nó, é que agora teremos multiplos nós ou maquinas, onde em cada máquina teremos um Worker do Airflow rodando, os quais serão responsáveis por executar as Tasks. Assim, suas tasks não serão executadas nos nós 1 e 2, mas sim pulverizadas entre essas maquinas ou Work Nodes.
Finalmente a aquiterua multi nó segue o mesmo fluxo de excução da arquitetura de nó unico, porém no final cadá Work Node irá buscar e executar as tasks na sua propria máquina ou nó.
Agora podemos nos perguntar:
“Como as Tasks são agendadas e executadas no Airflow?”
Observe que temos os principais componentes já abordados dispostos de forma mais abrangente e completa. Além disso temos um componente novo, nossa pasta com as DAG’s, qué é onde ficam armazenados nossos arquivos Python, ou seja, nossos pipelines de dados.
Agora imagine temos um arquivo python contendo um pipeline de dados na nossa pasta de DAG’s, o que acontece a seguir é o seguinte:
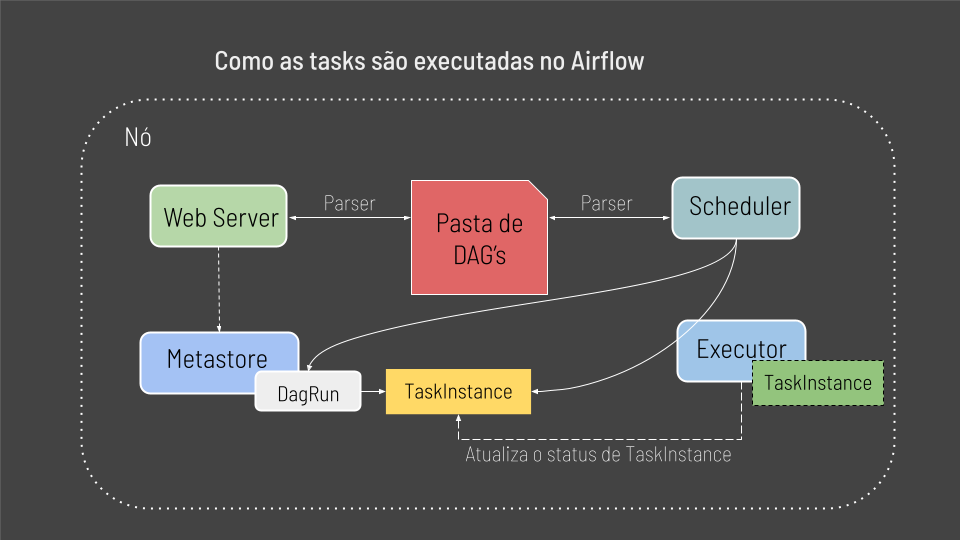
1 — Tanto o servidor Web Server quando o Scheduler irão parsear a pasta de dags para conhecer nosso pipeline de dados.
2 — Uma vez que tanto o Scheduler quanto o Web Server tem conhecimento do nosso pipeline de dados e estão prontos para dispara-lo, um objeto DagRun é criado com o status “running” no Metastore. E aqui tenha em mente que DagRun nada mais é uma instancia da classe DAG.
3 — Em seguida a primeira Task é agendada para ser executada. Quando essa Task está pronta para ser disparada no seu pipeline de dados, temos um objeto TaskInstance.
4 — Uma vez que o objeto TaskInstance e criado, o Scheduler o envia diretamente ao Executor.
5 — O Executor então roda o objeto TaskInstance e atualiza o status da Task no Metastore.
6 — Uma vez que a Task é completada com sucesso, o objeto TaskInstance é atualizado e finalmente o Scheduler verifica se o fluxo foi finalizado e se a DAG foi executada com sucesso.
7— Se a DAG foi executada com sucesso, o status do objeto DagRun é dado como concluido e o Web Server atualiza a interface.
Esse é o fluxo completo de como uma task é agendada e executada no Airflow.
Terminologias do Airflow
DAG
Um Directed Acyclic Graph, ou DAG, é um pipeline de dados definido no código Python. Cada DAG representa uma coleção de tarefas que você deseja executar sendo organizado para mostrar as relações entre as tarefas na interface gráfica do Airflow. Ao decompor as propriedades das DAG’s, sua utilidade se torna clara:
-
Directed: Se houver várias tarefas com dependências, cada uma deve ter pelo menos uma tarefa upstream ou downstream definida — mais adiante explicaremos esses conceitos.
-
Aciclic: As tarefas não têm permissão para criar dados autoreferrenciados. Isso evita a criação de loops infinitos.
-
Graph: Todas as tarefas são dispostas em uma estrutura clara com processos ocorrendo em pontos claros com relacionamentos definidos para outras tarefas.
De forma básica uma DAG é algo como:
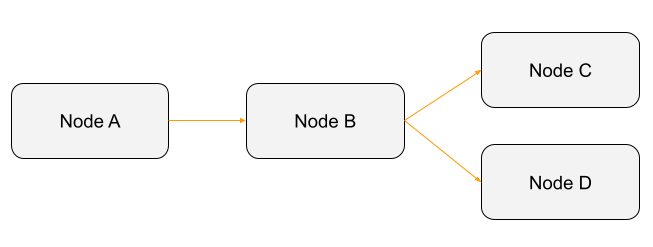
O mesmo não pode ser dito da imagem a seguir:
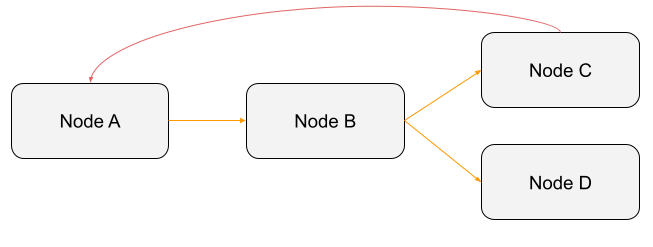
A imagem acima cria um ciclo. Como o Nó A depende do Nó C (relacionamento representado pela linha vermelha), que por sua vez, depende do Nó B e que depende novamente do Nó A, esta “DAG” não será executada. Quando uma DAG é acionada, um DAGRun é criado, que nada mais é que uma instância da sua DAG, com uma data de execução no Airflow.
Mas o que é um “Nó” no contexto do Airflow?
Operators
Em uma DAG do Airflow, um Nó nada mais é que um Operator. Em outras palavras, uma Task em sua DAG é um Operator. Um Operator por sua vez, é uma classe que encapsula a lógica de uma instrução especifica.
Por exemplo, caso deseje executar uma função python, usará o PythonOperator. Caso seja necessário executar um comando Bash, você usará o BashOperator.
O Airflow traz uma uma ampla gama de Operators que você pode encontrar aqui e aqui. Quando um Operator é acionado, ele se torna uma Task, mais especificamente, uma instância de Task. Um exemplo de Operator:
Como você pode ver, um Operator tem alguns argumentos. O primeiro é o task_id que é o identificador exclusivo do Operator na DAG. Cada Operator deve ter um task_id exclusivo. Os outros argumentos a serem preenchidos dependem do Operator usado.
Por exemplo, com o BashOperator, você deve passar o comando bash para executar. Com o DummyOperator, não especificar nenhuma instrução.
No final, para saber de quais argumentos seu Operator precisa, a documentação é sua amiga.
Dependencies
Como exposto anteriormente, uma DAG possui arestas direcionadas. Essas bordas direcionadas são as Dependencies em uma DAG do Airflow entre todos os seus Operators/Tasks.
Basicamente, se você quiser dizer “Task A é executada antes da Task B”, você deve definir a dependência correspondente.
O » e « significam, respectivamente, bitshift à direita e bitshift à esquerda ou definir tarefa downstream e definir tarefa upstream. No exemplo, na primeira linha, dizemos que task_b é uma tarefa downstream para task_a. Na segunda linha, dizemos que task_a é uma tarefa upstream de task_b. Não se preocupe, nós voltaremos às dependências.
Nossa primeira DAG
Existem 4 etapas a seguir para criar um pipeline de dados. Não se esqueça, seu objetivo é codificar a seguinte DAG:

Etapa 1: Faça as importações
A primeira etapa é importar as classes de que você precisa. Para criar uma DAG no Airflow, você sempre deve importar a classe DAG. Depois da classe DAG, vêm as importações de Operators. Basicamente, para cada Operator que deseja utilizar, deve-se fazer a importação correspondente. Finalmente, o último import geralmente é a classe de data e hora, pois você precisa especificar uma data de início para o sua DAG.
Etapa 2: Criar o objeto DAG do Airflow
Depois de fazer as importações, a segunda etapa é criar o objeto DAG do Airflow. Um objeto DAG deve ter dois parâmetros, um dag_id e um start_date. O dag_id é o identificador exclusivo da DAG em todas as DAG’s, sendo assim ele deve ser um parâmetro exclusivo. O start_date define a data em que sua DAG começa a ser agendada.
Além desses argumentos, 2 outros são normalmente especificados. O schedule_interval e o catchup.
O schedule_interval define o intervalo de tempo em que a DAG é acionada. A cada 10 minutos, diariamente, todos os meses e assim por diante. Duas maneiras de defini-lo, seja com uma expressão CRON ou com um objeto timedelta. Normalmente a primeira opção é a mais usada.
Por último, o argumento catchup permite que você evite a execução automática das DAGs de forma recorrente, ou seja, esse parâmetro define uma série de intervalos que o Scheduler transforma em execuções de DAG individualmente. O Scheduler, por padrão, iniciará uma execução de DAG para qualquer intervalo de dados que não foi executado desde o último intervalo de dados, no caso start_date. Se você não quiser acabar com muitas execuções simultâneas de uma DAG, geralmente é uma prática recomendada definir o parametro catchup como False.
Se *start_date estiver definido no passado, o Scheduler tentará preencher todas as execuções da DAG não acionadas entre start_date e a data atual. Por exemplo, se sua data_de_início for definida com uma data de 3 anos atrás, você pode acabar com várias execuções simultâneas da DAG ao mesmo tempo.*
Observe que, para criar uma instância de uma DAG, usamos a instrução with. A instrução with é um gerenciador de contexto e permite que você gerencie melhor os objetos. Nesse caso, um objeto DAG.
Etapa 3: adicione suas tarefas!
Após fazer as importações e criar seu objeto DAG, você está pronto para adicionar suas Tasks. Lembre-se de que uma Task é um Operator, portanto, com base em sua DAG, você deve adicionar 6 operadores.
Tarefa 1 — Treino do modelo
Primeiro, os modelos de treinamento A, B e C são implementados com o PythonOperator. Como não vamos treinar modelos reais de aprendizado de máquina, cada tarefa retornará uma precisão aleatória. Essa precisão será gerada a partir de uma função python chamada _training_model.
Observe que as 3 tarefas são muito semelhantes. A única diferença está no target_id de cada tarefa. Portanto, como as DAG’s são codificados em Python, podemos nos beneficiar disso e gerar as tarefas dinamicamente. Utilizando um recurso do python chamado list comprehension, é possível gerar as 3 tarefas dinamicamente.
Se você está se perguntando como funciona o PythonOperator, dê uma olhada na documentação aqui, você entenderá tudo o que precisa sobre ele.
Escolhendo o melhor modelo
Uma vez que a Task “accurate” ou “inaccurate” precisa ser executada baseando-se na precisão do melhor modelo, o BranchPythonOperator parece ser o melhor operator para isso. Ele permite que você execute uma tarefa com base em uma condição, um valor ou um critério. Se você quiser saber mais sobre ele, dê uma olhada aqui. O BranchPythonOperator é um dos Operators mais comumente usados.
Primeiro, o BranchPythonOperator executa a função python _choosing_best_model. Esta função retorna o task_id da da próxima Task a ser executada, no caso da nossa DAG, será retornado o valor “accurate” ou “inaccurate”, conforme mostrado nas palavras-chave de retorno.
Outra instrução que podemos observar é o xcom_pull.
Sempre que quiser compartilhar dados entre Tasks no Airflow, você deve usar os chamados XCOM’s, que são mensagens de comunicação cruzada, um mecanismo que permite a troca de pequenos dados entre as Tasks de um DAG. Um XCOM é um objeto que encapsula uma estrutura chave/valor, e esse valor é o que é compartilhado entre as Tasks.
Então, ao retornar a precisão da função python _training_model_X, criamos um XCOM com essa precisão, e com xcom_pull em _choosing_best_model, buscamos isso XCOM de volta correspondendo à precisão. Como queremos a precisão de cada Task na função training_model, especificamos os task_id’s dessas 3 Tasks.
Accurate ou Inaccurate
As duas últimas tarefas implementas são “accurate” e “inaccurate”. Para fazer isso, você pode usar o BashOperator e executar um comando bash muito simples para imprimir “accurate” ou “inaccurate” na saída padrão.
O BashOperator é usado para executar comandos bash e é exatamente isso o que é feito aqui.
Etapa 4: Definindo dependências
Agora que foram implementadas todas as tarefas, a última etapa é fazer o link entre elas ou, em outras palavras, definir as dependências entre elas. Faremos isso utilizando operadores bitshift.
Aqui, você diz que training_model_tasks é executado primeiro, depois que todas as tarefas são concluídas, choose_best_model é executado e, finalmente, accurate ou inaccurate. Lembre-se de que cada vez que você tiver várias tarefas que devem estar no mesmo nível, em um mesmo grupo, que podem ser executadas ao mesmo tempo, use uma lista com a instrução with.
Nesse caso a definição das dependencias é realmente básica, visto que executamos uma tarefa após a outra.
Assim, a DAG completa é a seguinte:
Conclusão
Se você leu esse post até aqui, muito obrigado, espero que esse material tenha sido útil e faça sentido pra você. É valido mencionar que ao longo do artigo muitos links foram disponibilizados e possuem um conteúdo extremante rico, além disso na seção de referências é possível encontrar mais alguns links uteis que foram utilizados para elaboração desse artigo que pode te ajudar a ampliar seus conhecimentos no tema assim como me ajudaram.
Além disso caso algum outro assunto relacionado ou não com o conteudo desse post te interesse ou tenha te deixado em dúvida, coloca ai nos comentários que ficarei muito feliz de esclarecer pra vocês em um novo post.
Lembrando que qualquer feedback, seja positivo ou negativo é so entrar em contato através do meu twiter, linkedin ou nos comentários aqui em baixo. Obrigado :)


